炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!

本文主要作者是吕昂和谢若冰。吕昂,中国人民大学博士生,研究方向为语言模型结构优化,导师为严睿教授;谢若冰,腾讯高级研究员,研究方向为大语言模型、推荐系统。
最近的一篇论文中,来自人大和腾讯的研究者们的研究表明,语言模型对强化学习中的奖励噪音具有鲁棒性,即使翻转相当一部分的奖励(例如,正确答案得0分,错误答案得1分),也不会显著影响下游任务的表现。
研究者解释道,强化学习对下游任务的提升,关键不仅在于奖励的准确性,而更在于模型是否能够产生高质量的思考过程。仅通过奖励模型输出中关键思考词的出现频率,而非基于答案正确性的奖励,语言模型依然能够在下游任务中取得非常高的峰值表现。这表明,强化学习对下游任务的提升,更多来源于让模型学会采用恰当的思考路径接近正确答案。而相关的解题基础能力,模型已在预训练阶段获得。因此,预训练阶段的能力提升依然至关重要。
研究者还展示了基于思考模式的极简奖励如何有效校准奖励模型,从而在开放性NLP任务中增强语言模型的表现,并使较小的模型也能通过强化学习成功获得思考能力。

论文概览
作者们首先研究了数学任务中奖励噪音对语言模型的影响,因为数学任务使用简单的规则校验,根据答案的正确性进行奖励,这使得人为控制奖励噪音变得非常简单(例如,通过将基于答案正确性的奖励函数结果进行p%的反转,正确答案得0分,错误答案得1分),从而便于研究。在训练Qwen-2.5-7B模型时,实验发现即使p值非常高,模型在下游任务中的表现几乎没有下降。只有当p值达到50%(即完全随机奖励)时,训练效果才开始崩溃。这一现象引发了一个重要问题:为何即便模型给出错误答案并且得到奖励,训练效果依然保持不变?
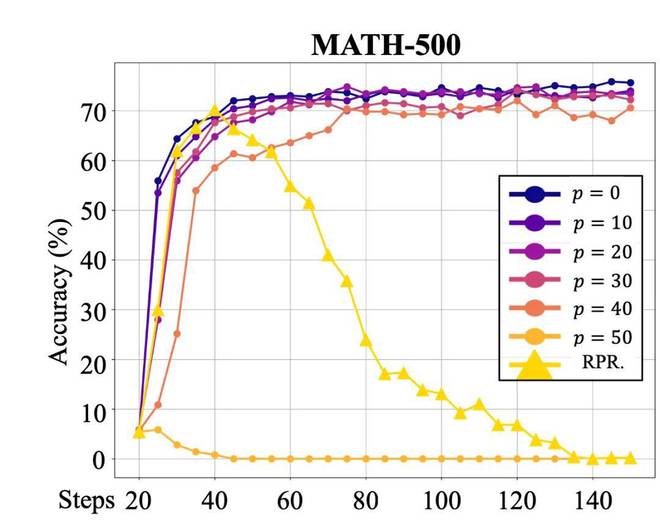 图1:使用不同程度奖励反转后的Qwen-2.5-7B在MATH-500数据集上的准确率变化,横轴为训练步数。
图1:使用不同程度奖励反转后的Qwen-2.5-7B在MATH-500数据集上的准确率变化,横轴为训练步数。针对这一现象,作者提出了一种可能的解释:尽管答案错误,输出中的某些信息依然为模型的输出提供了奖励的价值。研究者认为,这些有价值的信息反映在模型的思考过程上。当模型生成诸如「First,Ineedto」,「second,Iwill」,「giventhesefactors」,「finally」等思考模式时,无论最终答案是否正确,这一思考过程本身值得奖励。
为了验证这一假设,作者统计了在没有噪声奖励训练(即p=0)的情况下,Qwen-2.5-7B在数学任务中输出的高频思考关键词,并设计了一种非常简单的奖励机制——ReasoningPatternReward(RPR)。每当模型输出包含这些高频思考关键词时,便根据出现频次给予相应奖励,频次越高,奖励越大。
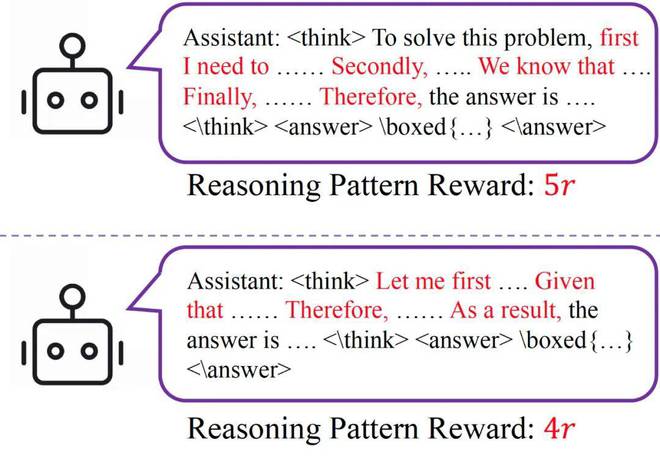 图2:RPR示意
图2:RPR示意仅使用RPR机制,完全不考虑答案的正确性,Qwen-2.5-7B仍然能够在MATH-500数据集上将准确率从5%提升至70%以上。尽管在后续训练中准确率有所下降,作者通过案例研究指出,这一下降源于RPR使得模型在获得正确答案后「过度思考」,从而导致输出超长无法提取正确答案。作者承认,仅使用RPR而不使用其他答案校验奖励可能会被模型「hack」并产生问题,但他们强调,此实验的目的是证明思考模式在能力提升中的重要性,而非为了获得最好的结果。
这一实验表明,强化学习中,语言模型的提升主要源自输出格式的转变而非新知识的获取:模型在RL期间采样到具有良好思维模式的输出,而这种思维模式能够提高模型逐token接近正确答案的概率。
以上基于奖励函数的实验结果让作者们意识到,这一发现也许对于基于奖励模型(rewardmodel)的强化学习后训练具有重要启示:由于奖励模型通常并不完美,输出中往往会包含噪声。如果语言模型能够在开放性任务中保持对奖励模型输出噪声的鲁棒性,那么我们或许不必过于追求极度精准的奖励模型,确保其「足够好」即可。
为验证这一点,作者在Nvidia-HelpSteer3数据集(一个多领域AI帮助性回复生成任务)上进行了实验。通过控制训练步数,训练了不同准确率的奖励模型,并用这些模型训练Qwen-2.5-7B。作者认为奖励模型的准确率与其提供的奖励噪声呈负相关关系,即奖励模型准确率越高,奖励噪声越低。模型在测试集上输出的回复由人类+GPT-4o判断帮助性、信息度、与综合质量。
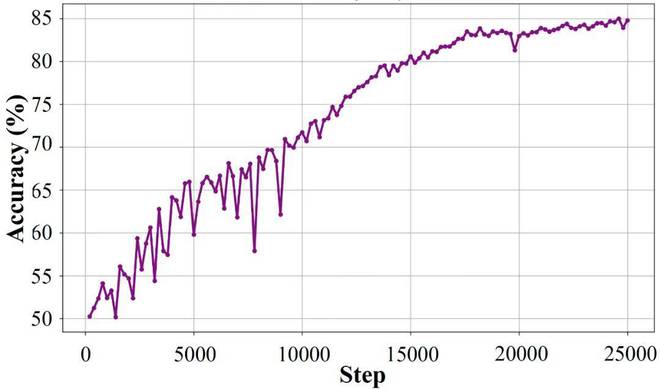
图3:奖励模型在HelpSteer3训练过程中,在验证集上的准确率,作者选取不同训练步数的checkpoint作为奖励模型进行训练。
实验结果显示,当奖励模型准确率超过75%时,不同奖励模型训练得到的语言模型在下游任务中的主观评测得分相似。这一现象与在数学任务中的观察相符,表明语言模型能够容忍一定程度的奖励噪声。然而,当奖励模型准确率低于75%时,训练效果显著下降;当准确率降至65%时,模型的表现大幅不如使用高准确率奖励模型训练得到的结果。这也许指出了Qwen-2.5-7B在该任务上的噪声耐受限度。
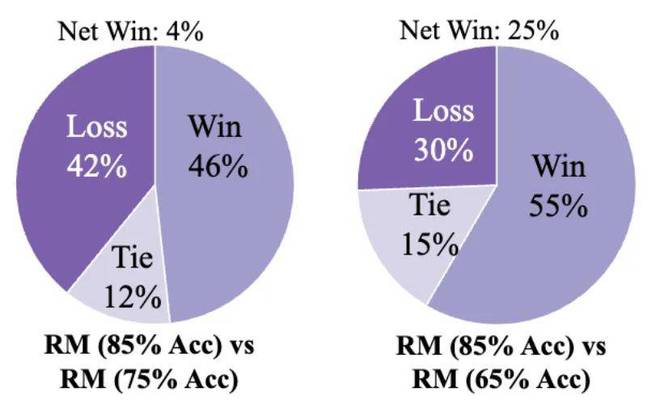 图4:不同奖励模型训练得到的语言模型在HelpSteer3任务中的主观评测表现
图4:不同奖励模型训练得到的语言模型在HelpSteer3任务中的主观评测表现这一发现或许对许多研究人员而言提供了慰藉:在很多应用场景中,我们不必过分追求奖励模型的高准确率,因为超过某个临界点后,进一步提高奖励模型的准确率对任务性能的提升将变得有限
作者们进一步思考,如果真的无法获得「足够好」的奖励模型,如何增强现有奖励模型以提升下游任务表现?
为此,作者提出通过RPR对奖励模型进行校准:如果某个输出被奖励模型评为低分,但其思考模式较好(即RPR得分较高),那么这个低分可能是一个假阴性,应该根据其思考模式通过RPR机制对奖励模型的输出进行补偿。通过这种方式,作者在HelpSteer3任务中验证了,即使奖励模型的准确率为65%,经过RPR校准后,模型表现接近原本85%准确率的奖励模型训练出的效果。同时,85%准确率奖励模型经过校准后,模型在下游任务中的表现进一步增强,突破了作者们所拥有的奖励模型质量的限制。
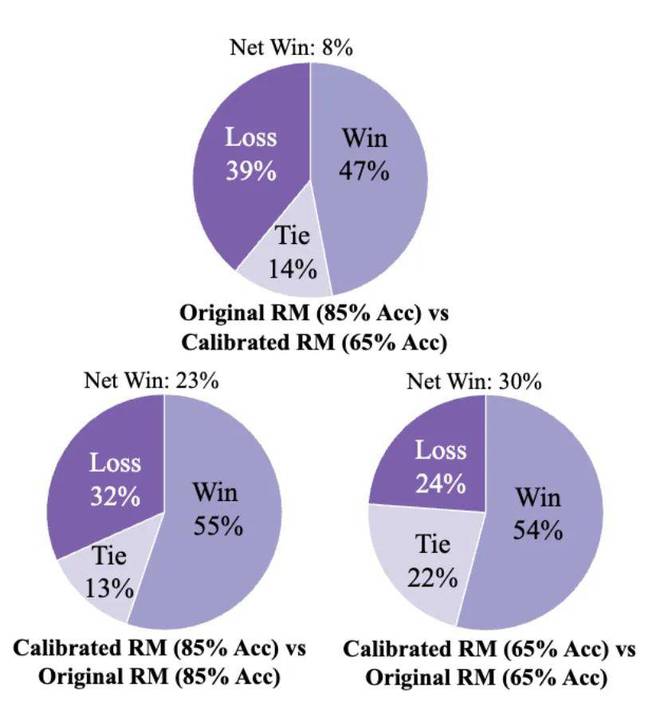 图5:经过RPR校准后,所有奖励模型训得的语言模型质量都有提升。
图5:经过RPR校准后,所有奖励模型训得的语言模型质量都有提升。作者们的另一个重要发现是,即便使用作者所拥有的最精确的奖励模型(准确率85%),Qwen-2.5-3B在HelpSteer3任务上发生了训练崩溃,表现为输出长度急剧下降,仅剩数十个token。但经过RPR校准后,3B模型成功完成了训练,避免了崩溃并获得了良好的效果,并且在很多复杂的开放任务中,比如根据指令做PPT,呈现出良好的解题思路。
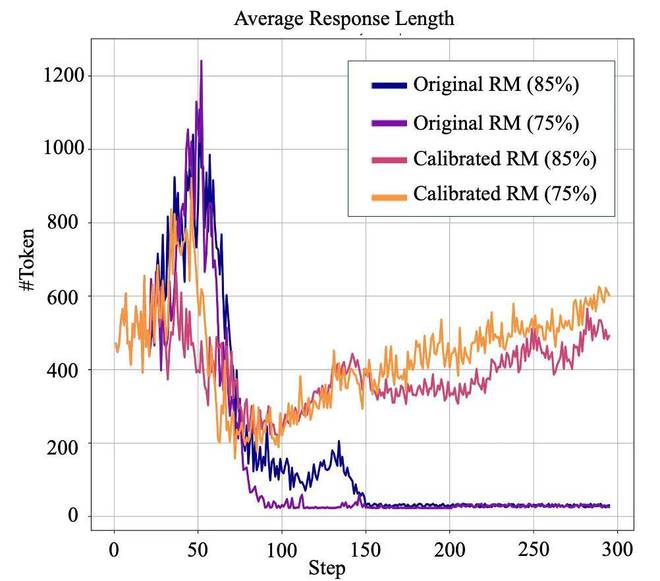
图6:经过RPR校准奖励模型后,3B的模型也可以在HelpSteer任务上成功训练;而使用未校准的奖励模型,RL发生了崩溃。
研究者们希望通过展示语言模型对基于结果的奖励噪声的鲁棒性,以及单独使用RPR获得下游任务提升的结果,来强调强化学习对语言模型的影响更在于改变其输出风格,形成良好的思考模式,而非教授新知识
此外,思考模式的重要性在使用奖励模型进行训练的开放性任务中得到了验证,也为强化学习后训练算法的改进提供了新思路。
作者指出,模型预训练技术的增强仍然值得持续投入,因为如果强化学习只专注于思考模式的培养,语言模型预训练阶段的能力依然会对下游任务构成瓶颈(例如文中对Llama3的实验表明,由于Llama3预训练模型难以生成较高质量的思考路径,导致其在各个任务中的表现和抗噪音能力远逊色于Qwen模型)。
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP 编辑:财经 来源:市场资讯
